Los modelos de inteligencia artificial prometen cada vez más: cumplir con todo tipo de tareas al nivel de los máximos expertos humanos en cada vez más campos y con velocidad y precisión cada vez mayores. Pero hay una pregunta que importa más que esas credenciales: ¿cuánto tiempo puede trabajar una IA sola, en una tarea real, sin que nadie la supervise?
Una investigación reciente de METR —una organización dedicada a evaluar riesgos de inteligencia artificial— intentó responder exactamente eso. Los investigadores crearon 170 tareas reales de programación e investigación: escribir código, arreglar bugs, analizar datos, configurar sistemas. Trabajo concreto que cualquier programador o investigador hace en su día a día.
La idea fue medir la dificultad de cada tarea según cuánto tiempo le llevaría a un experto humano completarla. Una tarea que a un programador le lleva 10 minutos es más fácil que una que le lleva tres horas. Después, pusieron a trabajar a los modelos de IA en esas mismas tareas y registraron en cuáles tenían éxito.
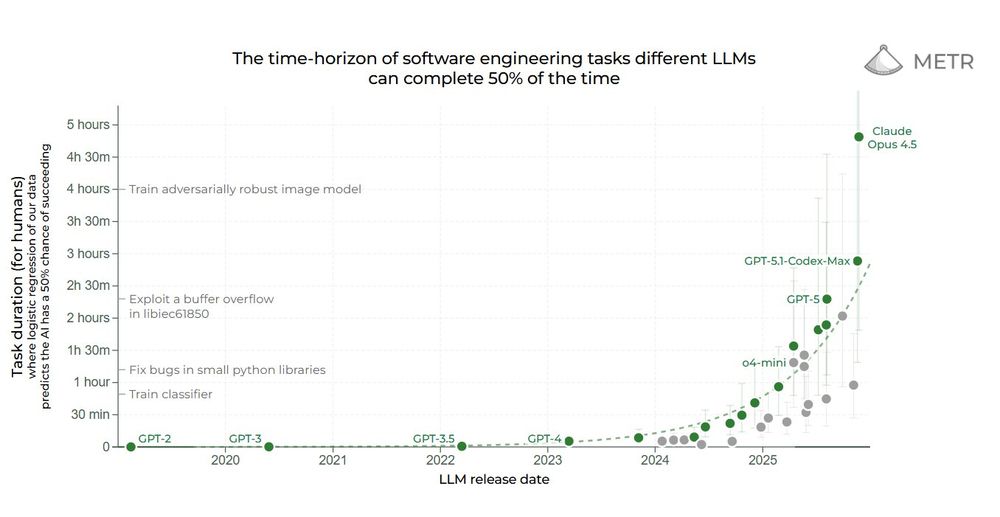
El resultado: los mejores modelos actuales logran completar con éxito (50% de las veces) tareas que a un humano experto le llevarían aproximadamente una hora. Si la tarea es más corta —media hora, 20 minutos— la IA tiene más probabilidades de éxito. Si es más larga —dos, tres, cuatro horas— las probabilidades caen drásticamente.
A esto le llamaron "horizonte de tiempo": la complejidad máxima de tarea (medida en tiempo humano) que un modelo puede manejar de forma autónoma con razonable confiabilidad. Y lo más importante: ese horizonte se duplicó cada siete meses desde 2019. Aquel año, GPT-2 apenas llegaba a tareas de segundos. En 2020, GPT-3 alcanzó un minuto. En 2023, GPT-4 llegó a cinco o diez minutos. Y ahora, en 2025, los mejores modelos superan la hora.
Qué midieron y cómo
METR evaluó 13 modelos de IA —desde GPT-2 hasta los más recientes— en 170 tareas reales de programación e investigación. No se trató de preguntas teóricas ni problemas de matemática, sino de trabajo concreto: escribir código, arreglar bugs, analizar datos, configurar sistemas. Tareas que cualquier programador o investigador hace en su día a día.
La metodología fue simple pero rigurosa. Primero, expertos humanos completaron esas mismas tareas y registraron cuánto tiempo les llevó. Luego, los investigadores corrieron los modelos de IA en las mismas tareas y midieron su tasa de éxito. Al cruzar ambos datos, obtuvieron el horizonte de tiempo: la duración de las tareas donde cada modelo logra un 50% de éxito.
Los números muestran una progresión dramática. GPT-2, lanzado en 2019, apenas podía completar tareas de segundos. GPT-3, un año después, llegó a un minuto. GPT-4, en 2023, alcanzó los cinco a diez minutos. Y los modelos más recientes, lanzados en 2024 y principios de 2025, superan la hora. La curva es exponencial y no muestra señales de desaceleración.
La proyección que cambia todo
Alan Daitch, especialista en IA y fundador de Digodat, comentó el estudio en un posteo reciente. "Todavía es poco, pero la curva viene creciendo de forma exponencial", escribió. "Si sigue así, en 2026 podríamos ver agentes capaces de trabajar semanas completas sin supervisión. Y eso cambia todo".
¿Qué significa en la práctica? Un modelo capaz de trabajar un mes de forma autónoma podría desarrollar aplicaciones completas, realizar investigaciones científicas extensas o gestionar proyectos complejos de principio a fin. No se trata solo de responder preguntas o generar texto, sino de ejecutar proyectos reales con todos los pasos intermedios: planificar, implementar, probar, corregir errores, iterar.
El estudio también midió un "horizonte del 80%", es decir, cuánto tiempo pueden trabajar los modelos con una tasa de éxito del 80% en lugar del 50%. Ese número es más conservador: Claude 3.7 Sonnet, el más capaz en esta métrica, llega sólo a 15 minutos con esa confiabilidad. La brecha entre ambos horizontes revela que, incluso cuando los modelos pueden completar tareas largas, no lo hacen de forma consistente.
Dónde siguen fallando las IA
Los investigadores identificaron patrones claros en los fracasos de los modelos. Las tareas "desordenadas" —aquellas sin feedback claro, que requieren juicio o contexto específico— siguen siendo un desafío grande. Por ejemplo, los modelos tienen casi 100% de éxito en tareas que a un humano le llevan menos de cuatro minutos, pero caen por debajo del 10% en tareas de más de cuatro horas.
Eso revela una limitación clave: la falta de contexto. Los modelos funcionan mejor en tareas autocontenidas, donde toda la información necesaria está disponible de entrada. En proyectos reales, donde hay que entender decisiones pasadas, convenciones no escritas o prioridades implícitas, los humanos con experiencia siguen siendo mucho más eficientes.
Otro punto débil: las tareas que requieren múltiples intentos sin feedback inmediato. Los modelos actuales dependen de poder verificar rápidamente si van por buen camino. En problemas donde el feedback es costoso o ambiguo, su rendimiento cae notablemente.
Lo verdaderamente valioso
"La habilidad más valiosa no va a ser programar ni saber usar bien ChatGPT", escribió Daitch. "Va a ser saber orquestar agentes: qué tareas darles, cómo combinarlas y qué cosas no dejarles hacer. Los que lo logren van a poder escalar negocios enteros con muy pocos empleados".
La idea es clara: si los modelos pueden trabajar de forma autónoma durante períodos cada vez más largos, el trabajo humano se desplaza de ejecutar tareas a definirlas, supervisarlas y combinarlas. Ya no se trata de escribir cada línea de código o hacer cada análisis, sino de diseñar el sistema de tareas, elegir qué automatizar y qué no, y revisar resultados.
Los investigadores de METR reconocen que sus tareas de laboratorio son más limpias y estructuradas que el trabajo real. Pero incluso con esas limitaciones, la tendencia exponencial es robusta: aparece en múltiples conjuntos de datos, con diferentes metodologías, y se sostiene a lo largo de seis años. Pequeños errores en la medición podrían cambiar la fecha de llegada de la IA de un mes en uno o dos años, pero no alteran la dirección general.




















.")



